两年间一点事
一瞬间已过去两年,两年间历经许多事,不论是工作上,还是生活上,起起伏伏、恍恍惚惚,这就是人生:充满跌宕、充满挑战、充满未知,显得不平淡。趁下雨天,写点什么,一可以度过听雨时间,二是总该记录点什么,免得想找却不知在哪个文件夹。
两年间,从最初的简单资讯推荐开始,慢慢开始独立承担安居头条、实勘、房源推荐、海外、集客家、问答、有料、举报和安选、虚假房源、房源聚合、生成文本、Flink研究、信息治理、自动巡检等,小有小点,大有大点。
最初
在实验室自己鼓捣了很多东西,graphLab的一个开源python框架,已记不清是干啥的,只记得很多数据处理模块可以用,那会花了一个星期学习安装和使用;然后,就被论文所打断,开始思考该写什么论文,在研一时,所选课程做的大作业是推荐、文本分析,使用svd做电影推荐,使用svm做微博自杀的预测,以及贝叶斯的餐馆评价分类等,因此,不知不觉选择文本方向,自己开始看论文,比较分散的看,最后确定大致的思路,做评论的情感分析。
接着,开始自己爬取评论,写了一个爬取京东、爬取旅游网站的评论,然后解析出评分星级,作为语料,那会还把数据放到数据堂售卖,只卖出去不到5份,没有达到提现要求,也就没去管它了。之后,通过svm判断主客观,再根据情感库做情感值的计算,另外把这些框架搬到了spark上实现,自改spark下的svm,就这样水过了毕业。。哦哦,另外,还发了两篇论文,一篇自己的,一篇实验室合作的,起码达到了毕业要求。
接着,跟大学毕业一个人去杭州黄山浪了一个星期一样,答辩结束入职公司前,去了南宁、南京,收心开始码农生涯。一开始熟悉各种流程,git代码提交流程,在实验室代码自己管理,也没用过;公司内部开发平台,spark离线在线集群;对外接口的开发;资讯表的熟悉、海外的表熟悉、二手房源的熟悉;就这样开始承接项目,带我的小师傅却在9月离职了,那段时间,凭借自己记忆与主动咨询,记录了一些操作流程,就这样自己独立操作起来,不用太多的指导。
开始
依稀记得那会先看hive脚本,还傻傻地记录每张表,每个hive的实现逻辑,一开始很是困难,读起来十分不流畅,后来才发现其实只要知道源表以及业务逻辑就可以了,离线逻辑也就完全理解了。
头条那会做单页的推荐,因为资讯分了好几个库,唯一的标示并非id,而是需很多字段,单页的推荐协同过滤用得很多,师兄便让我用新的方法,尝试了word2vec计算标题的语义相似,每天增量计算,在crontab里设置定时搞了许久;还学习caffe使用图片相似做,搞了两个星期,不知是效果不佳还是什么,尽然没继续做下去。
接着实勘推荐经纪人,在师兄的指导下开始在spark里写job逻辑,却一直提交到线上不成功,第一次加班到23:00才下班。设置这个job不仅在crontab里设置调起,还需要解析集群的job,每天去停掉它以及重启,写了一个python脚本抽取出spark集群上指定的job名,并且学supervisor设置job启动。不过,后来由于经纪人常变动自己意向,每天需要解绑,这个项目就此搁置;
房源的推荐,最先是过期单页的5个推荐位,要求不同的逻辑,把之前的逻辑做了复用,却第一次出现产品投诉说推的不准,而后调了小区的限制,就此解决了,页面效果也比之前页面提升了2倍多。
海外项目,一开始其他同事负责,因为她的离职自然而然落到我身上,海外资讯主要是rank排序,历经三个版本,海外地产基本能套用现有逻辑,改些许业务逻辑。
集客家项目,跟实勘推荐差不多,使用到flink做实时房源的添加,接口逻辑也比较复杂,分了售卖和出租、求租和求购,改了两个版本,最后产品的离职以及新项目就此搁置。
问答
因为之前单独自己研究问答排序,比如知乎、overstack等,结合pv+时间+问题质量+回答质量,打分排序,问答在12年至今也没改版,所以落到我这边,开始改pc首页,做了很多推荐位,问题、经纪人、问答关键词等,页面上线后效果提升10%,而boss比较关心首页推荐占比,那会是10%-15%之间徘徊,boss希望占比30%以上,那会调了很多逻辑,一直没成功,最近却在40%以上;后来历经三个产品,问答算是走到正轨,日均回答经纪人1.3万,uv40万,大家都比较鸡血的干,希望破5万。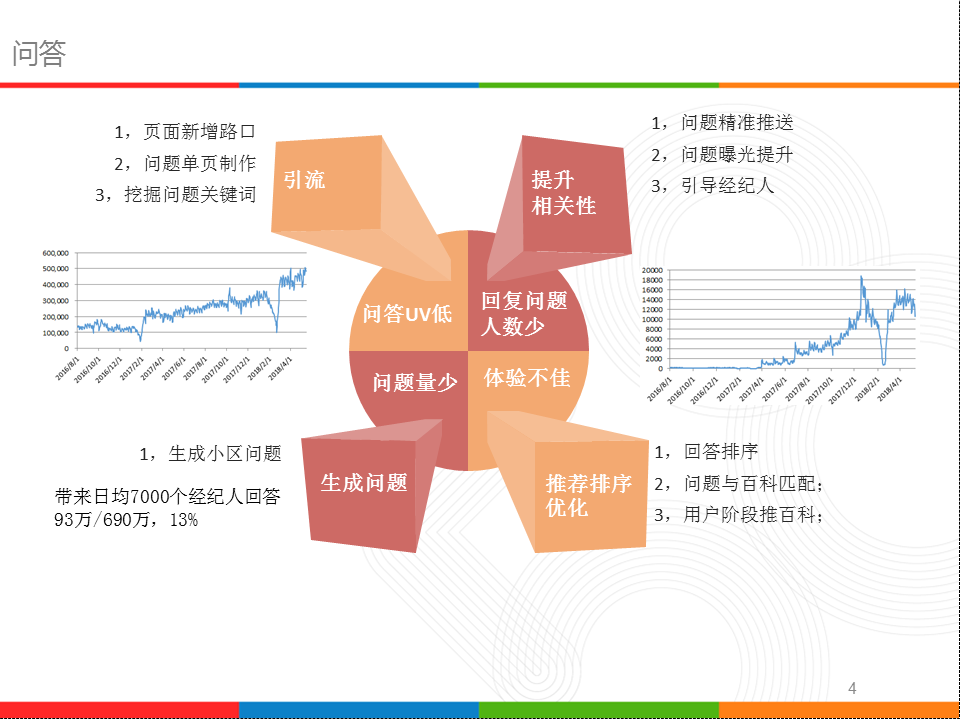
问答面临的四个问题:回复人数少、每日问题少、UV低、体验不佳,针对这几个问题,都做了针对性的项目,在相关性上、问题生成山、推荐排序上下足功夫,相关性主要是给经纪人推相关问题,这里的相关问题定义为小区问题,小区的选取涵盖历史回复小区、发房小区、附近小区、相似小区等;因为小区覆盖面广,也就提升了问题的曝光数。我们做过数据分析,一个问题在50个人看到下,被回答的概率达90%以上。而小区问题,我们从不从分类维度进行生成,保证每天有量、有不同问题覆盖到,并且控制量。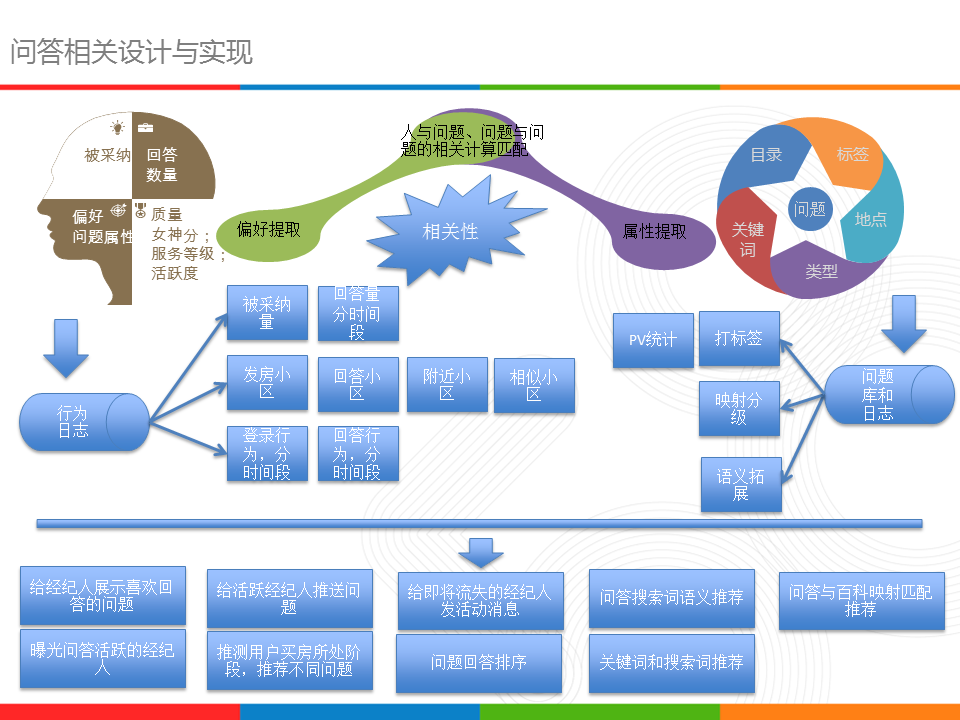
正如图中所示,问答整个项目都围绕相关性计算,从经纪人角度、用户角度、问题角度,提取相关基本数据,然后进行匹配计算,为业务提供服务实现。工作量主要是导入小区问题,计算搜索词语义相似,以及各个增量全量计算并提供服务数据,有些写到hbase有些写到wtable里。
问答一年时光里的工作,除了技术上hive、spark、语义计算,Flink批处理,以及增量全量计算,还有应对各业务逻辑的实现,也是投入激情最多、积极的一项,与产品思想切合以及后端、分析师的合作密切离不开。
有料
问答在17年经历一年的折腾,效果提升明显,日均经纪人数从100涨到1.3万,UV从10万涨到46万,而且集团战略的大内容,这两点促进了有料的诞生,把平台所有资讯(新闻、导购、视频、内行人文章等19类)集中个性化展现,做房产领域的“今日头条”。
平台的资讯历经三次调整,第一次是从头条开始,资讯类别的底层分在不同库,涉及三个技术团队,那时的工作比较掣肘,很多数据获取不全,只能小部分拿来计算;第二次改版,将内容团队整合,底层数据也进行了迁库,后端的小伙伴燕灿也整理很全,逐步把资讯整合,涉及8张表;另外,为了计算的准确点和获取方便点,我也逐渐剔除埋点细化,使得离线和实时统计算解析方便许多,这时再跟燕灿不断讨论下,把大内容的整个框架合起来,从底层数据流到前端显示,以及各个业务服务的存储和接口全盘整合;然而,却在这时产品动荡很大,技术团队也跟着改变,新版的资讯大改造接着而来,把原先分散的资讯归到一张表中,另外,日志也进行了迁库,过程中数据缺失、发码的不匹配、以及各个服务接口的改版接踵而来。
当前的有料频道,展示的数据逻辑如下所示:
当用户进入到有料频道,会实时读取三个数据:资讯全量表,含头条分值—-用户头条按日期分层排序,同日期内按效果排序;质量分值—-用户个性化一个因子,保证业务逻辑,即某些资讯排前,类别打散等功能;离线每日计算的偏好权重值,这部分是在用户点击和曝光样本上经逻辑回归计算得到,主要是类别、标签、区域、板块、时间、质量等权值;用户偏好具体分值,这个分值再Flink的窗口下实时计算,以用户设备粒度计算。结合这三部分数据,用户屏幕呈现出的资讯是从搜索库中拉取出,按照资讯信息、偏好权重、具体偏好分值进行命中加权排序得到的。这里权重、偏好、质量影响每个用户的排序。
这时具体的流图,分离线和实时,离线是在hive里计算经post到rabbitMQ来更新到线上全表;并且组织点击和曝光样本,在spark下离线采用逻辑回归得到权重值,需注意的是线上搜索权值不能为负值,所以,又对权值进行处理,将负值变正直,变动过程的直差按正权重值比例平摊到原先正权值上,得到新的权重值;实时部分,读取两个kafka流,是因日志分了两个库源,然后在Flink下进行点击流和曝光流计算,得到用户的偏好具体值,以及实时操作的一些逻辑如置顶以及样本保存等。
有料数据是日均28万ud,转化率25%,搜索的架构,为了更精确用户的偏好,标签需要打细点、分散点,后面搭建文本资讯的自动打标签服务迫在眉睫,以及对每个用户的偏好计算需要新的存储方式,以便记录时间段的偏好。
AI-NLP
自然语言处理,从实验室开始我就接触,那时没做基础的系统学习,来到公司后逐渐在闲暇之计把NLP最相关的分词、词性标注、提取等进行了整合,另外,拓展出一些应对业务逻辑需求服务,房产领域的词库、语义计算、词向量计算、文本生成等,大致的框架如下所示: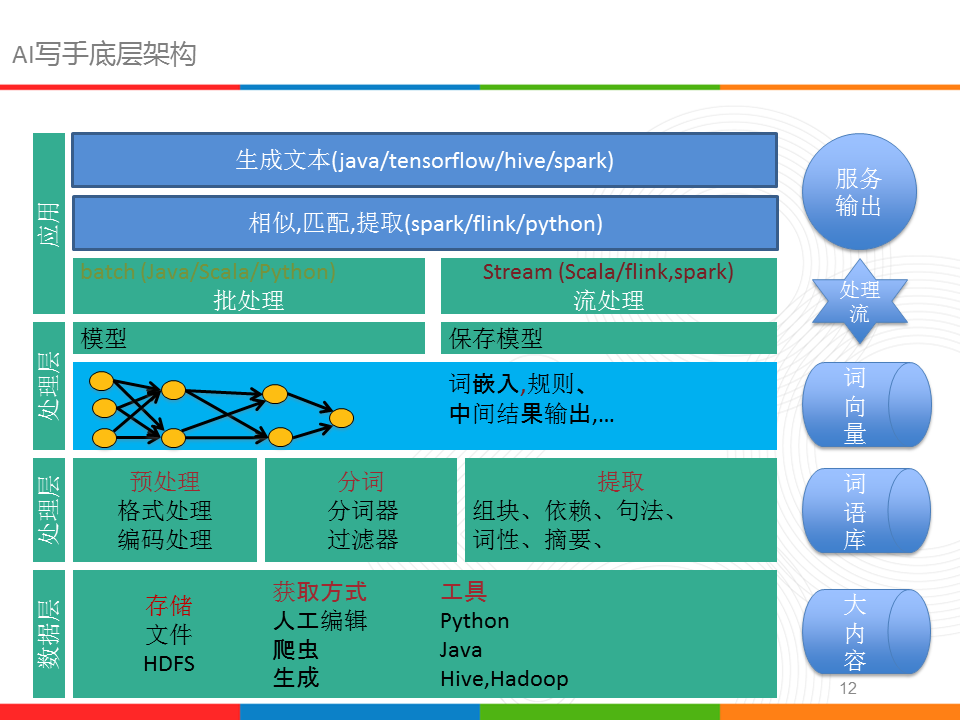
底层的数据在hive里组织,把平台的文本数据做了聚集,另外也写了一些爬取数据程序,所有数据存在hdfs上。
接着是处理层,做了编码的处理,去除非法字符,把分词器以及自定义词性过滤器还有组块抽取等组成一个模块,这部分模块一开始在java里写的,后来慢慢地迁移到scala,为了在Flink和spark下用;词向量的计算用的是python写的,有个麻烦事算出来的词向量需要拷贝写到hbase里,比较费时也费力;最终,在spark高版本下找到word2vec的训练方法,所以迁到spark下计算,这样模型也存储在hdfs上了。在业务使用时用的多的是分词、抽取、语义计算、生成等,主要面对线上业务。
说点其他事情吧,数据存储一开始没有集团介入,是在ajk集群上的,后来迁到58,这时库间数据没法打通,需要机器间scp来拷贝,后来scp的命令被禁止,转而使用nc拷贝,慢慢地也变得不行了,而使用sftp,数据间的存储不在同一集群,很是麻烦。
在boss没下定决心搞点评生成前,nlp的模块比较散,设计在flink中,写了tf-idf以及读取word2vec等,另外计算两两间的相似性,涉及到稀疏向量与密集向量转变,在flink下批处理异常的慢,后来逐渐的迁到spark下,因为集团机器没有flink。在spark下也不断添加其他外部源,主要是与集团各种架构对接,wtable,wlist,scf等。
文本生成,是词的序列问题,生成最好的是诗歌宋词,因为这些有固定的格式和模板,词间的连续短,生成出的效果可以在人为联想中得到全部语义;而一段话、一段文章却不同,没有固定的格式和模板,难以界定词连续对主题的判断。正如图中所示,靠模型来计算词连接的概率,加之受限条件得到新的文本。我已经实现了三种概率计算方法,完全统计概率,即从语料中计算词的下一个词的概率,很是费时,每次生成要遍历全部样本,生成一段话需要遍历N遍语料;第二种是LDA的主题分布,从语料训练得到词-主题分布,主题-词的分布,先选择主题,再从主题下挑选词;第三个序列模型,RNN训练输进去词序列,来得到词间的连接概率。
最初的想法是根据宋词的生成规则,抛弃宋词的平仄、韵脚等固定,完全统计词的下一个词的概率来生成,如图中第一个例子,我扣除一些词,把这句话当做模板,然后在样本中找下一个词填充,得到新的序列文本,意思其实不知所云,因此长文本需要更严谨的限制条件;接着我限制主题,按照给出的主题下选词进行依次生成,效果比上一个例子好些,起码知道序列文本讲的大概内容范围是房产领域,细节上还是很拗口的;接着尝试固定文本的词性顺序,想法是文本的连接存在词性的先后顺序,更能接近语义连贯,从结果看确实如此,读起来连贯性好很多。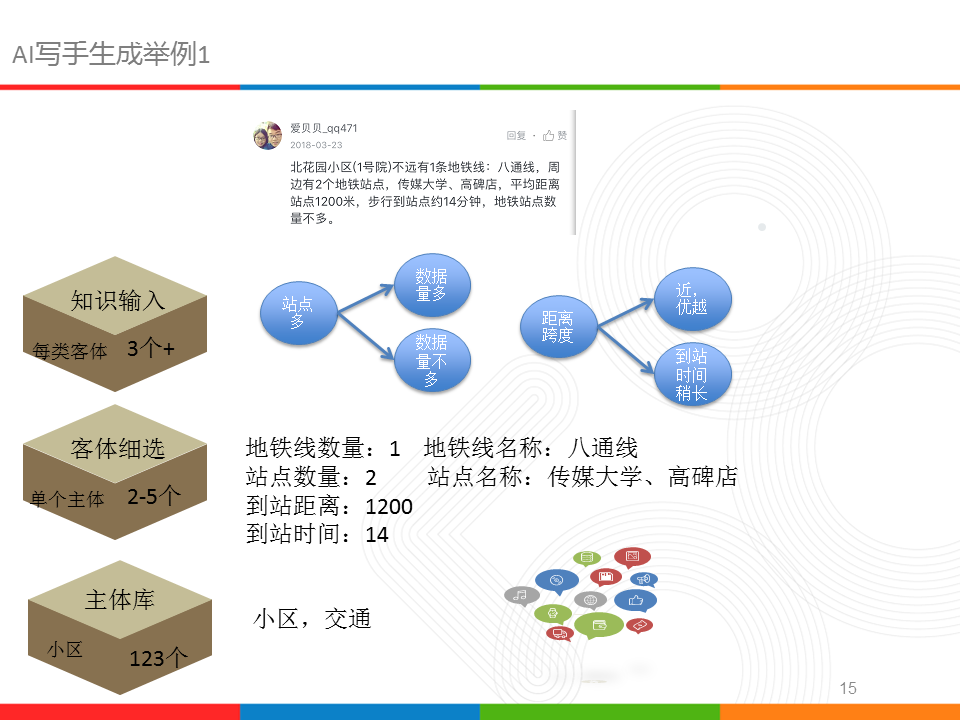
然而,上述三个例子的结果都存在不尽如人意,我尝试加入知识输入,固定一个主体,然后在主体范围内挑选3-5个客厅,这些客体作为输入关键词,结合知识和规则组织成最后的一段序列文本,从结果看,十分符合人为编辑语义,只是对一组客体需要输入一堆的知识,比较费时费力,另外还要考虑口语化等特点。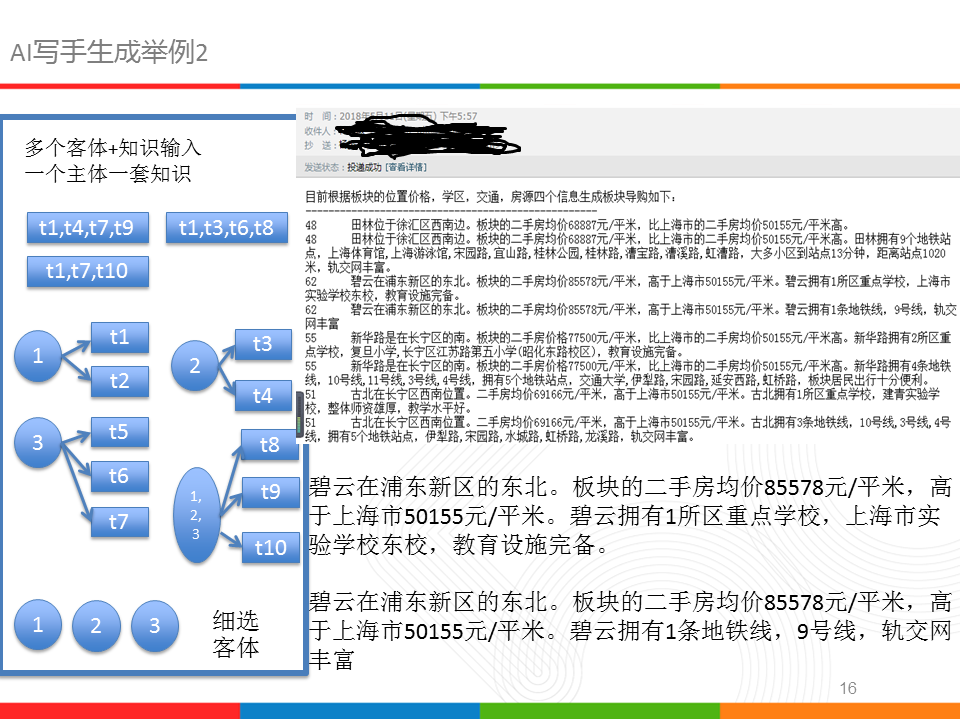
主要的思路如图的左侧,每个客体配备2-3个知识,然后,人为固定客体的先后顺序,这样就得到基于客体的一段话;同样,我们固定主题的顺序,就得到一段文章,如右侧所示;必须承认,这种方式人工干预还挺多,而且目前的文章,在主体上还需引入更多信息。
举报
举报与安选担保其实是一起启动的,安选担保涉及到机密就不做过多解说;举报是给浏览房源用户提供一个举报虚假房源功能,当房源被举报后,经纪人需要去申诉,提供的申诉材料会经人工审核。而这期间会发生恶意举报、集中举报等现象,因此需要对举报来源做分析和过滤,堵住恶意举报的来源,减少对经纪人的干预。分两阶段进行,首先,对恶意举报数据进行统计分析,设置不同的临界点过滤,举报上限、举报频率、举报成功率等,第二阶段,模型自动识别,主要是提取三方数据:被举报的房源、被举报的经纪人、举报发出的设备,从这些方面提取出96个维度信息,当然还按1,3,5,7,10天进行了分层。1
2
3
4
5
6
7
8
9
101,用户浏览房源行为
根据浏览日志,点击日志,举报日志,用设备号关联打通数据,得到用户发出举报前浏览该房源,
及该房源所在小区(板块,城市,面积,价格,户型,房屋类型)的数据。
然后,再分时间段前1天,前3天,前5天,前7天,前10天统计。
2,用户举报行为
根据举报日志,得到用户发出举报前举报该房源,
及该房源所在小区(板块,城市,面积,价格,户型,房屋类型)的数据。
然后,再分时间段前1天,前3天,前5天,前7天,前10天统计。
以及举报时所处的时间段(一天分5段)
3,房源价格与小区均价的偏离度,房源的uv和pv。
举报判定是判断举报有效否,为0/1二分类问题,采取gbt模型,融合多个决策树,每个决策树对某些特征进行构建,最后根据每个棵树的预测值与树权重得到最后的预测结果。1
2
3
4
5
6训练:2017-10-15前(含15日)的举报
测试:2017-10-16至2017-10-22日的举报
结果:auc=0.889,accurcy=0.908,f1=0.910
预测0 预测1
实际0 250.0 43.0
实际1 72.0 897.0
踩过的坑,主要是设备之间日志的关联,比较复杂;另外,特征的选取和统计,写了很多逻辑;最后的最后大坑,样本输入到spark下,因为drop的关系,没有真正的删除掉特征,把label也加到了特征里。
后来思考过用场景化解决举报判断,即通过行为的序列,分析出恶意举报的行为场景,在spark的频繁项挖掘可以解决如此问题,也做过尝试,日志样本集没有时间去整理,但因其他项目的插入边没进行下去。
房源侧
房源的推荐主要是二手房和海外地产推荐,基于协同过滤会预先算出房源之间的推荐数据,然后,考虑房源之间的业务限制逻辑;线上使用时会实时根据用户点击行为,记录用户点击历史,然后从历史房源中找推荐的房源,此为第一候选池,接着再限制业务逻辑,得到第二层候选池,最终以接口形式将推荐数据返回。基础以及最简单的接口流程即如上所示。
然而,这没有加入用户的偏好属性,因此,会在实时计算过程中记录用户的房源偏好属性,并且保存,这些偏好会与房源进行匹配,从而得到一个房源的偏好排序,这是升级改版的一个推荐流程,这时会涉及到偏好权重的计算,需要点击和曝光日志,工作量其实是在组织样本,然后采用逻辑回归做权重的训练;实时依靠kafka以及spark的流处理。
这时的处理特征其实限定在了偏好的选取,偏人为点,没有加入其它未使用到的特征,后续才引入了xgboost以及ffm等模型,因为是其他组员的工作,所以不便过多讲解,时间花在特征的拉取上,多多益善,涉及特征编码等,训练模型其实可以套用copy到spark集群上。复杂的模型可以训练出一批候选,主要是排序上。
当然,复杂的模型可以得到好的效果,个人比较倾向于特征在时间上的分段以及衰减上。
另一个房源的项目是房源聚合,实现多个相似房源的聚集,使得页面展示时能够把相同房源做一个展示,聚合的因子除了地理信息维度,还有房源的本身属性。
其他的如虚假房源检测,本质上平台(除了自营的链家)无法确认房源真实性的,拿不到房源的真实主人信息,只可凭借发房者的提供证据来判别,当证据是假时,那么房源也就被误判为真的。所以,只能从一些显性的点去判别虚假疑似度,比如价格、面积、图片、视频等。
另外,其他同事也用二分类模型去解决,搂出房源申诉确定的结果,从房源属性测来判别,效果听说不错,正确率80%,实际效果还在检验中,本人比较倾向从申诉审核判断的因子出发,以及经纪人发房行为、提供证据等去挑选特征,靠谱点。
Flink周边
Flink是专门的流处理框架,相比spark的批处理,flink在流处理方面显得更有拓展性和丰富性,有更多的流窗口操作。在16年7月开始研究使用,在9月开始跑线上的业务,后来慢慢地接了几个,目前跑了两个;很惭愧没有过多地去研究源码,本来写了一个flink下的tf-idf,想提交到flink的github上,因为不懂怎么提交也就作罢了;后来,公司方向转为专注spark也就没有去研究了。
其他的其他
其他的诸如小点,治理、业务接口逻辑什么的,另外还有与集团服务接口的使用,要放到hive或者spark或者flink下,需要包配置等,另外,集群跑的版本问题等,还是在业务逻辑的实现上。
闲暇之计,学习学习nlp等课程,国外国内的,每周看一些,论文什么的,思考一些点、一些方向,还有与师兄们以及行业内的大牛们聊聊,参加会议等等。
技术流涵盖,hive、spark、flink、java、python等,tensorflow也自学起来。
最后的话
两年,承认心浮躁,想想理下做了什么,还有什么值得做的,未来的规划等等,写出来其实方向也就明朗了,下一步就是积极主动地跑起来,不落后、不怀旧、不幻想。。。。


