nlp--generate text document
分词隐马尔可夫,从字的状态中训练得到概率,可用于其他识别,如地名、人名等;
条件随机场是搭配与提取用的有效方法;
序列模型,RNN,LSTM是神经网络模型,从N-gram的不同序列中训练得到预测的概率,这里的预测可以是字、词、句子等;
词性tags的分析,可引申出组块的抽取;
句法和依存关系,类似于状态打标签,根据词的不同状态,得到依赖关系;
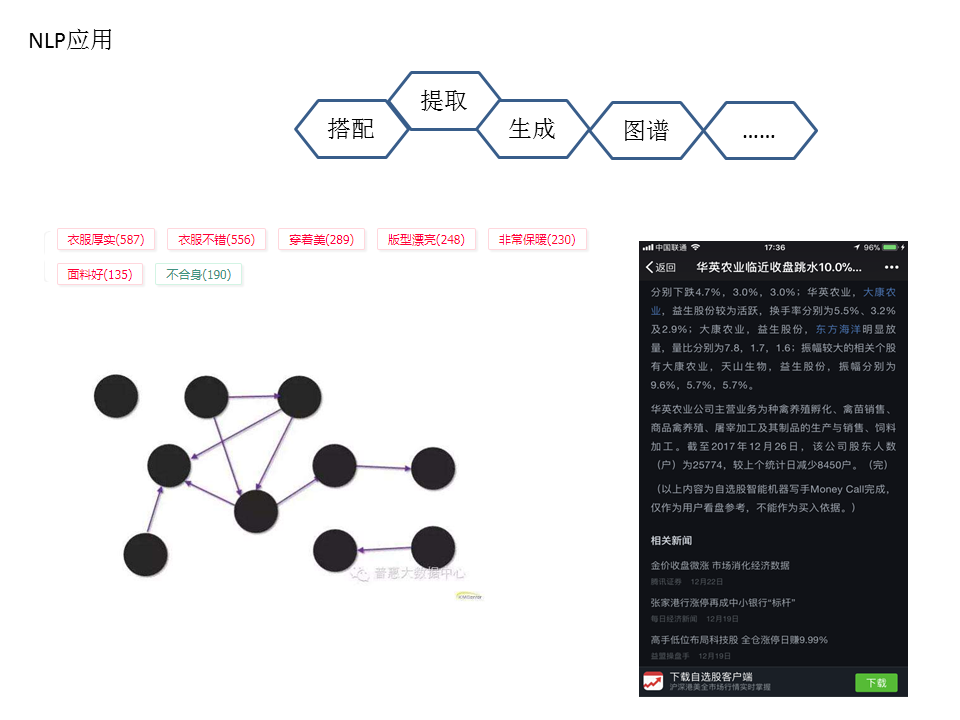


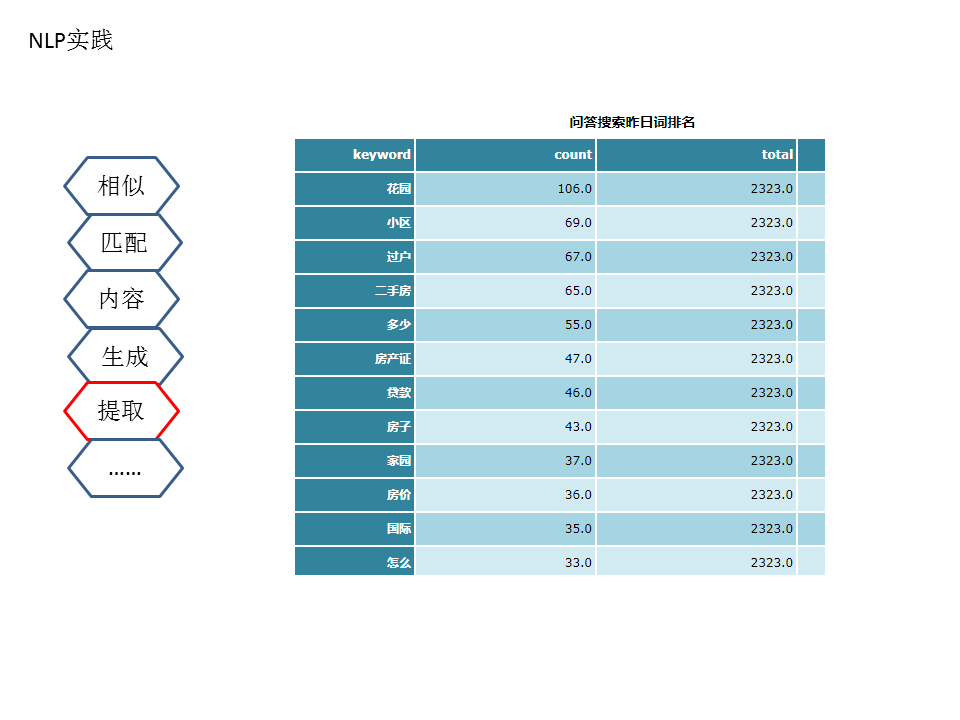
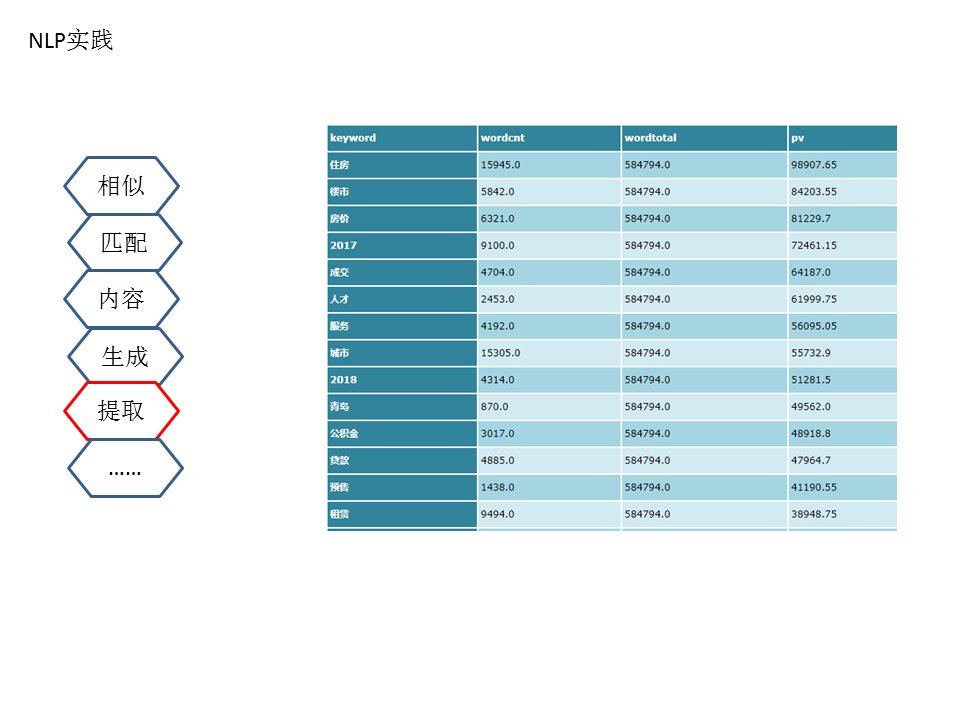

架构中除顶层红色外,都是已经上线在已有业务中的应用,顶层的红色是今后将研究与实现的应用。在已经应用的项目里,各个模块比较分散,还需进一步整合,达到调用方便。
此外,还需拓展中间层的处理和多种模型尝试。
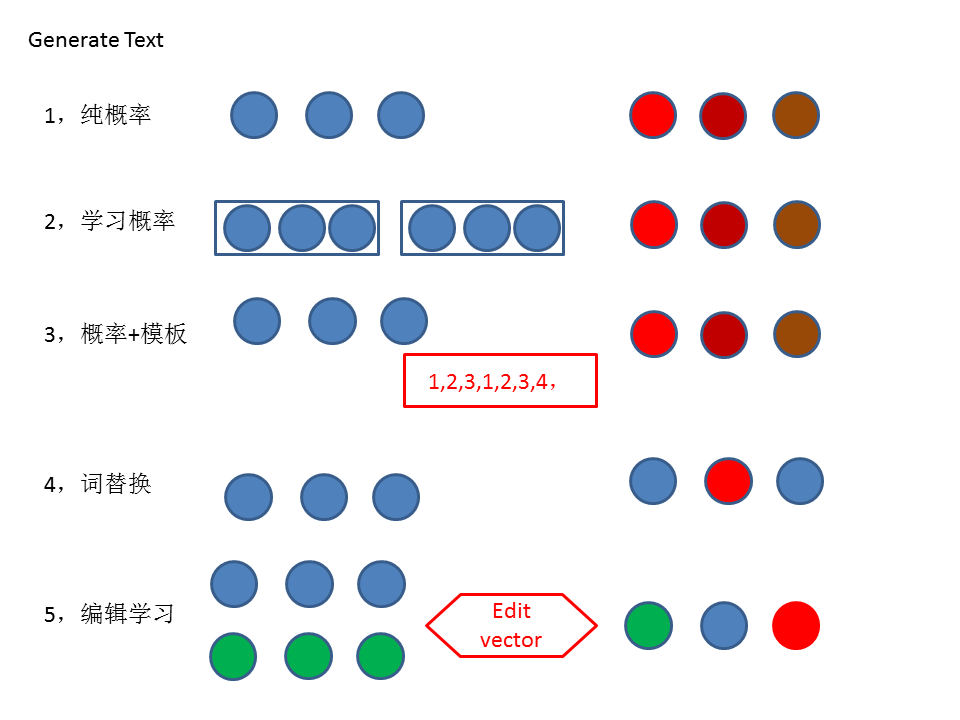
目前已有的生成模型主流是概率推算,分统计概率和学习概率,统计概率主要是传统的统计数据求概率,已词频为特征;而学习概率以神经网络的序列模型为主,借助n-gram的上下文,庞大的序列串,以及能够存储少许记忆的LSTM神经元,训练得到一批推算概率的权重,从而预测出下一个字、词、句子。
而目前在句法上,神经网络难以达到人的理解水平,注意力机制也是很难符合预期效果。在实际业务中,采取规则的方法颇多,即主要关键信息可单独拎出来计算,然后其余的描述信息人为给定足够多的模板,以及替代的变换词、句子,最后组装成文本,效果上能够达到人编辑的目标。但是,模板终究是有限的,

因此,统计概率是最简单的,但是无法解决语义,即“人吃草”的问题,学习概率可以弥补这一缺陷,受限于n-gram的序列长度,不能照顾太长的序列;而神经网路一是神经元数量少,与文本语言的目标不相符合,另外语言是网结构,需要发散、需要其他辅助、需要沉淀,不是链式结构,从前几个状态就能够推导出的;
突破的点,个人认为在以下几个方面:
1,加大序列,体现更长久的记忆,能够弥补语义以及环境,但是,不是长久之计;
2,领域资料,即构建符合语言的网结构,把词与相关的领域做一个存储网状,或嵌套,虽然笨重但是是最有效的;
3,目前网络是链式的训练,以图像识别为例,输入图像、卷积、池化、LRN、卷积、池化、全连接、softmax等,这些操作是链接上一个再操作的,无法获取到额外信息,语言是变动的,不是静态的,静态的可以用这种链式的不断迭代去优化,语言却不行(个人意见,欢迎拍砖)。所以,需要新的网络结构来训练语言,
流计算是当前最为火的工具,Flink已经被阿里改造城Blink,并且反哺了社区,在经过阿里集团内部的实践后,新的Flink版本能够解决诸多业务问题,也是十分稳健的;
流数据的关键是要把流与静态表映射,业务型的当前已表结构多,需要吞吐量大,以及可靠的文件系统,还需要保证性的流处理;
再者,在标签上,用户的轨迹不在是单个的,而是多维的,这些多维的体现在一个公司的生态中,也体现在社会广大的生态中,存储轨迹的方式需要做新的更新,不再是以前条记录的形式,而是能够随时间拓展、随业务拓展的结构,并且格式需要能够快速插入和更新,是一种嵌套和索引的方式。


