NLP 18年规划
内容在17年经过头条的爆发后,内容在18年将是个风口;各大互联生态拉新用户的手段已经接近黔驴技穷了,在传统上无法指数增长用户,留下两条路径:
一是收购其他平台,补充用户;而是做好已有的用户留存率。而内容平台就是其中之一。
各个公司在AI的应用都瞄准精简人力,客服、问答、审核等密集型业务;在推荐、连接等意图型业务中也在不断优化提升。

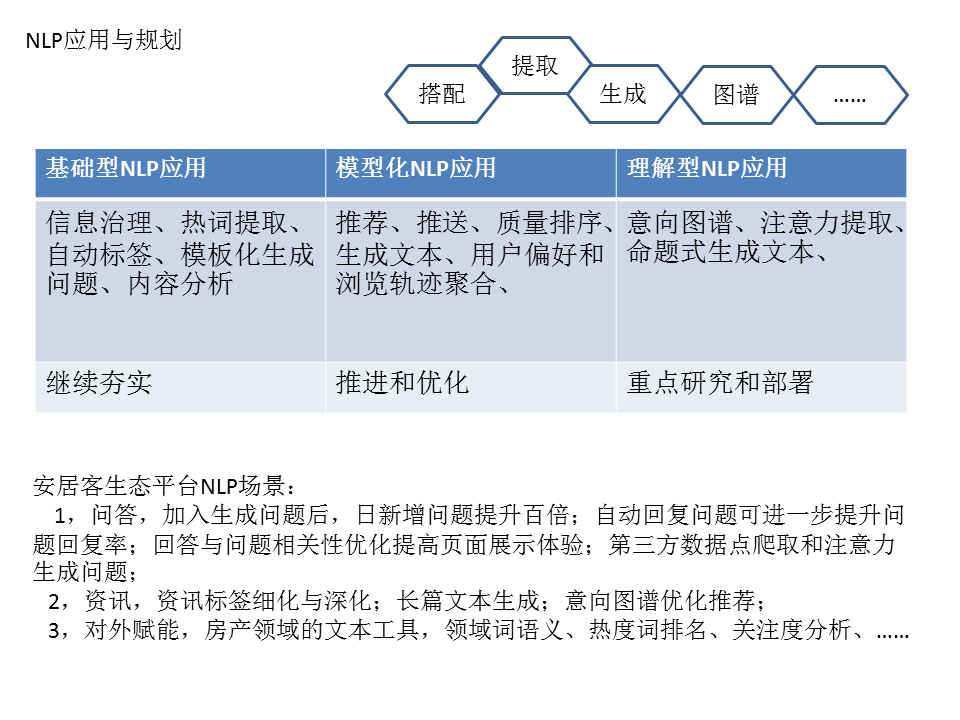
在过去的一年时光里,从推荐开始,慢慢接收文本类业务,单页的推荐资讯从协同过滤、热度、用户喜好等推荐方式出发,到精准推问题、增加问题的曝光、拉升新增问题、优化内容排序等,到后续慢慢起步的资讯个性化推荐,涉及的文本技术从基础型慢慢地向理解型转变。
信息治理应用于描述信息中脏数据或认定非法的检测;热词源于对昨日资讯的点击,便于观测词的注意力度,可应用于问题的生成,提升回答率和点击率;自动标签的生成,主要在资讯上,仅限于统计数据的标签还未细化到语义层面,下一步可将其往深处拓展,延伸标签背后的语义,丰富偏好;
模板化生成文本已经在问题中试水,每日带来问题量以及回复人数,比其他问题的效果明显,这部分将可以借助外部数据源,生成更多更丰富的问题;
在推荐和推送中,紧跟“相关性”的度量,考虑到曝光度和回复的比值关系,一方面背后挖掘人的相关点,另一方面控制页面的类别排序,还有活动的激励,总之,紧跟两个原则,一是给出感兴趣的,二是拉动活跃;
在偏好和用户浏览轨迹上,目前仅仅是统计用户在某一个时间点或时间段的标签值,没有可回溯单个用户偏好的数据源,可以设计新的存储方式,把时间带上,使用不断嵌套方式,这样在做用户画像或者推荐时,获取用户的偏好就更快捷和精准;
树状的知识图谱在查询中能够体现好的作用,而在识别意图中,需要的是网状,并且额外的延伸信息;
在特定场合下或领域下,某些词是具有吸引力的,能够抓住用户的注意力,通过这方面的挖掘、抽取和生成,可以实现高吸引的文本;
另外,命题式的生成是一个挑战,即给定一个主题,完成既定字数的文章,需要很大的词汇组织,以及领域图谱;
NLP的实践,从数据源出发,到预处理,模型构建,应用输出。数据源除了人工录入外,可爬虫获得;文本的预处理离不开格式和编码规范,在同一个平台下需要统一格式统一编码;之后的分词、提取、过滤等也是NLP不可或缺的操作,才生的结果可以是中间结果,也可以应用到简单的业务场景,比如词的统计,以及语义的延伸等;之后的模型构建,针对不同的目标进行训练和保存,当前有词向量和生成文本等;对外的应用紧跟产品需求,当新的需求加进来,也许需要从源头数据源开始,重复如此步骤。
除了顶层的理解型构建,其余模块可进行整合,也可以进行拆分,为了整体耦合,最好是整合在一个平台内,对外提供调用;然后,新增的在各个模块进行添加。

NLP的任务,最多是跟数据打交道,需要了解数据源开始,把数据源进行整理,达到简单可用的地步;然后是,对数据的预处理,得到切分好的原材料;
还有很多值得研究的地方,值得探索的当是意向图谱的构建和命题式的生成。



